Advancing Video and Image Segmentation: A Deep Dive into SAM2

Ever wondered how a single tool could revolutionize the way you interact with visual data?
Introducing a ground-breaking innovation that’s not just an upgrade but a game-changer. This cutting-edge model sets new benchmarks in speed, versatility, and precision, transforming how we approach everything from complex video editing to in-depth research. Ready to dive into the key features and real-world applications that are reshaping the way we handle visual data? Join us as we uncover the innovations that are changing the landscape of how we work with images and videos.

Interesting Features and Applications of SAM2
What makes SAM2 stand out in the crowded field of AI models? Let’s take a closer look at its defining features and the real-world applications that are reshaping the way we interact with visual data.
One of the standout features of SAM2 is its “promptable” nature. You can simply click on or draw a box around the object you want to segment, and SAM2 does the rest. You can also refine your selection by adjusting the prompts as you go, and the model will adapt in real-time, updating the segmentation. This type of interactivity makes SAM2 not just powerful but also incredibly user-friendly.
Speed is crucial when dealing with videos, and SAM2 does not disappoint. It processes videos in real-time, ensuring the segmentation is both fast and accurate. Whether you are working on a single image or a series of video frames, it handles it all with ease.
But what truly sets SAM2 apart is its versatility. It’s a foundation model trained on an enormous dataset, delivering consistent, high-quality segmenting results. The best part? It works out-of-the-box even for objects and visual domains it hasn’t encountered before.
Real-World Applications of SAM2: Endless Possibilities
SAM2 can be integrated into larger AI systems to enhance multimodal understanding, contributing to more comprehensive AI models that can interpret complex scenes. Its fast inference capabilities are perfect for applications like autonomous vehicles, where quick and accurate object detection is crucial. It could also speed up the creation of annotation tools, making the training of computer vision systems more efficient.
Imagine selecting and manipulating objects in live video with just a few clicks — SAM2 makes it possible. It opens up new possibilities in video editing, enabling more control and innovation in generative video models. The model’s ability to track objects across video frames could be used to monitor endangered animals in drone footage or assist surgeons during medical procedures by localizing regions in real-time camera feeds.
Showcasing SAM2: Interactive Video Segmentation Demo
Curious about the power of SAM2? In this demo, we’ll highlight its cutting-edge capabilities through a dynamic GIF, demonstrating SAM2’s interactive video segmentation features.
Explore the Features:
- Erase: Seamlessly remove unwanted elements from your video with precision.
- Gradient: Apply smooth transitions to your segmented objects for a polished, professional look.
- Burst: Highlight and segment rapidly moving objects in real-time, ensuring nothing is missed.
- Spotlight: Focus attention on specific areas or objects, making them stand out clearly across frames.
- Pixelate: Obscure sensitive or private areas within your video while maintaining the integrity of the rest.
- Overlay: Add layers of information or effects over segmented objects, enhancing the visual narrative.
See SAM2 in action: Watch the GIF below to experience how SAM2’s interactive features can transform your video editing and analysis tasks. With these tools at your fingertips, you’ll be able to manipulate video content with unmatched precision and creativity.
Try it out for yourself: You can try video editing with SAM2 at SAM2 Demo.
Evolutionary History of Segmentation Models
The world of artificial intelligence and computer vision is advancing at an extraordinary pace. Meta AI’s Segment Anything Model (SAM) was a ground-breaking step in image segmentation, enabling users to effortlessly isolate objects with simple prompts. Now, the introduction of SAM2 is taking this innovation even further, expanding capabilities from static images to dynamic video content.
But how did we get here? Let’s take a quick look at the evolution of segmentation models that paved the way for SAM2:
2015
- SegNet: An encoder-decoder architecture with upsampling in the decoder for pixel-wise segmentation, known for its simplicity.
- UNet: Symmetric encoder-decoder with skip connections, excelling in tasks requiring precise localization.
2016
- FPN: Multi-scale feature extraction using a pyramid structure, effective for objects at different sizes.
- PSPNet: Uses pyramid pooling for multi-scale context understanding, improving segmentation in complex scenes.
2017
- DeepLabV3: Employs atrous convolutions and spatial pyramid pooling for capturing multi-scale context.
- LinkNet: A lightweight encoder-decoder model with skip connections, efficient for real-time tasks.
2018
- PAN: Combines attention with pyramid features for improved focus across scales.
- DeepLabV3+: Enhances DeepLabV3 with a decoder for better localization.
2019
- LightSeg: A lightweight encoder-decoder model optimized for resource efficiency.
2020
- MANet: Uses multi-scale attention for refined feature capture.
2021
- SegFormer: Transformer-based model combining a simple MLP decoder with a transformer backbone.
- MaskFormer: Treats segmentation as mask classification using transformers for improved performance.
- STDC: A fast, efficient model using dense concatenation for real-time applications.
- A2FPN: Enhances feature pyramids with attention mechanisms for better detail and context capture
2022
- Mask2Former: Advances MaskFormer with refined transformers for superior segmentation across tasks.
2023
- Segment Anything Model (SAM)
Meta’s SAM made segmentation highly accessible and versatile. With promptable segmentation, it allowed users to segment any object in an image with just a few clicks, generalizing impressively to new objects and domains.
2024
- SAM 2
Taking everything SAM offered and expanding it to videos, SAM 2 brings memory components for object tracking across frames, making it a unified solution for both image and video segmentation
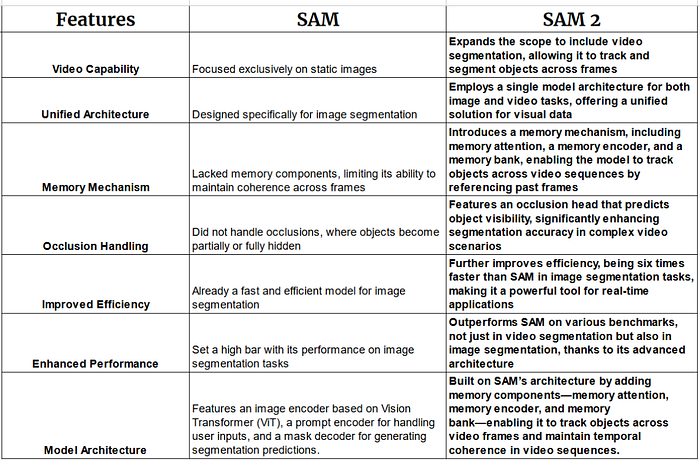
SAM revolutionized image segmentation with its prompt-based flexibility and ability to generalize to new objects without extra training. Paired with the vast Segment Anything Dataset (SA-1B), it set a new industry standard. Now, SAM2 elevates this by extending those capabilities to video segmentation, introducing features that promise to transform how we interact with dynamic visual data.
SAM vs SAM 2
Key Enhancements in SAM 2:
Decoding the Magic of SAM2: The Engineering Behind Seamless Video Segmentation
Let’s dive into the architecture of SAM2, unraveling how it masterfully combines Vision Transformers, Masked Autoencoders, and Promptable Visual Segmentation to bring video and image segmentation to life.
1. Vision Transformers and Image Encoding: The Neural Network Powerhouse
Imagine piecing together a jigsaw puzzle where each piece represents a tiny part of the full picture. In SAM2, Vision Transformers (ViT) handle this process by treating patches of an image or video frame as individual tokens. The ViT then figures out how these tokens relate to one another to reconstruct the complete scene.
Why It’s Important: The Vision Transformer acts as the brain of SAM2, allowing it to understand the detailed structure of a scene — like determining where one object ends and another begins, even if parts are obscured or in motion.
Mathematical Insight: The ViT operates using a self-attention mechanism. It calculates how important each token (patch) is in relation to all other tokens, which helps the model focus on the most relevant parts of the image:
Breaking It Down:
- Q (Query): The current token being considered.
- K (Key): The tokens it’s being compared to.
- V (Value): The information to extract.
- Softmax: Normalizes the relationships so they sum to 1, assigning importance levels.
This mechanism allows SAM2 to piece together the full image, ensuring it understands the scene’s complexity, even with hidden or blurry areas.
2. The Heart of SAM2: Memory Attention and the Memory Bank
Memory Attention is the key innovation that sets SAM2 apart, making it excel at video segmentation. While processing a video, SAM2 doesn’t just treat each frame as isolated; it remembers what it saw in previous frames to ensure that its predictions are consistent over time.
How It Works: As SAM2 processes each frame, it stores the information in a Memory Bank — much like short-term memory. When a new frame arrives, SAM2 uses Memory Attention to access this bank, applying what it learned from previous frames to understand the current one better.
Memory Attention Mechanics:
- Self-Attention: Focuses on relationships within the current frame to extract the most critical features.
- Cross-Attention: Compares these features with stored memories, ensuring consistency across frames. This cross-referencing allows SAM2 to recognize objects as they move, change, or even disappear temporarily.
The Memory Bank: This is a dynamic storage system where the most recent frames are kept in a FIFO (First In, First Out) queue. This ensures that SAM2 always has the most relevant information at hand, while older, less useful data is gradually replaced.
Why It’s Important: This memory system allows SAM2 to track objects seamlessly across a video, handling challenges like occlusions, motion blur, and changing perspectives. It’s this capability that makes SAM2 particularly powerful for tasks that require long-term consistency and accuracy in video analysis.
3. Promptable Visual Segmentation: The Interactive Edge
One of SAM2’s standout features is its ability to interact with you directly through Promptable Visual Segmentation (PVS). Whether you’re editing a video or analyzing an image, PVS allows you to guide SAM2’s segmentation process with simple inputs like clicks, bounding boxes, or masks.
How It Works: Suppose you’re working on a video and need to focus on a specific object — let’s say a person. With PVS, you can click on the person, and SAM2 will automatically segment that individual across the entire video. If SAM2’s initial attempt isn’t perfect, you can refine the segmentation by providing additional prompts, such as clicking on a missed area or drawing a box around the object. SAM2 learns from these interactions, continually improving its accuracy.
Why It’s Important: PVS transforms SAM2 from a mere tool into a collaborative partner. You’re not just passively accepting the model’s output — you’re actively shaping it to meet your needs. This interactive feature is especially valuable in fields like video editing, medical imaging, and any application where precision is crucial. PVS empowers you to achieve the exact results you want, making the segmentation process more efficient and tailored to your specific goals.
4. Mask Decoder: Refining the Output
After SAM2 processes the frame and integrates your inputs, the Mask Decoder generates the final segmentation mask. This mask provides a detailed outline of the object, clearly distinguishing it from the surrounding environment.
Handling Ambiguity: Sometimes, user inputs can be ambiguous. For example, if you click near two overlapping objects, it might be unclear which one you’re targeting. The Mask Decoder handles this by predicting multiple masks and refining them based on additional data or metrics, ensuring that the final selection is the most accurate.
Mathematical Insight: To measure how well these masks align with the actual object, SAM2 uses a metric called Intersection over Union (IoU):
Breaking It Down:
- Area of Overlap: How much of the predicted mask overlaps with the actual object.
- Area of Union: The total area covered by both the predicted mask and the actual object.
A higher IoU score indicates a better match, helping SAM2 choose the most accurate mask for each frame, even in challenging scenarios with multiple objects.
5. Masked Autoencoders: Training the Model to Understand Incomplete Data
SAM2’s ability to handle real-world data, which is often incomplete or noisy, is largely thanks to its training with Masked Autoencoders (MAEs). MAEs help SAM2 learn how to reconstruct missing or obscured parts of an image, making the model more robust and reliable.
Visual Analogy: Picture a photo with parts covered by sticky notes. A Masked Autoencoder works by training SAM2 to guess what’s behind the sticky notes and fill in the gaps accurately. This process teaches SAM2 to predict missing information, which is critical when dealing with imperfect data.
Mathematical Insight: The training process involves a reconstruction loss function, such as Mean Squared Error (MSE), which measures the difference between the predicted and actual pixel values:
Significance of Reconstruction Loss: This loss tells us how well SAM2 is doing at predicting the hidden parts of an image. A lower reconstruction loss indicates that SAM2’s predictions are close to the actual data, meaning the model is effectively learning to handle missing or noisy inputs. By minimizing this loss during training, SAM2 becomes more adept at dealing with real-world scenarios where data isn’t always perfect, such as videos with low light, motion blur, or occlusions.
Putting It All Together
SAM2’s architecture is a harmonious blend of advanced techniques, working together to create a model that’s not just powerful but also adaptable. Whether you’re segmenting objects in a single image or tracking them across a video, SAM2’s combination of Vision Transformers, Memory Attention, Masked Autoencoders, and Promptable Visual Segmentation makes it an indispensable tool in the AI toolkit. With SAM2, you’re not just using a model — you’re engaging with an intelligent system that learns, adapts, and collaborates with you to make complex video segmentation tasks intuitive and effective.
SA-V DATASET AND TRAINING OF SAM-2
🎥 To understand the power of SAM2, it’s essential to explore the SA-V dataset .
What is the SA-V Dataset?
“Alright, let’s dive into the SA-V dataset — this is the largest Video Object Segmentation dataset ever created. Imagine this: 650,000 masklets from over 50,000 videos filmed in 47 different countries. It’s absolutely massive! To give you some context, this dataset has 15 times more videos and 60 times more masklets than previous giants like BURST and UVO-dense. We’re talking about over 12,000 minutes of video content, with resolutions ranging from 240p to 4K, totaling a staggering 4.2 million frames. Yeah, it’s that big!”
💻 Training SAM2 with SA-V
So, how is SAM2 trained to become such a powerhouse? Let’s dive into the cutting-edge process behind its development.
The journey began with a rigorous pre-training phase on the SA-1B dataset, which consists of high-resolution, static images. To drive the learning process, they employed the AdamW optimizer, a state-of-the-art algorithm known for its adaptive learning rates and weight decay, ensuring robust and efficient training. Layer-wise learning rate decay was also used, allowing each layer of the model to learn at an optimized rate tailored to its depth.
They didn’t stop there. To further enhance SAM2’s robustness, they used data augmentation techniques like horizontal flipping and resizing images to 1024x1024 pixels. These methods introduced a variety of scenarios, helping the model to generalize better and become more versatile.
The real magic, however, unfolded when SAM2 transitioned to the SA-V dataset and began training on additional video datasets such as DAVIS, MOSE, and YouTubeVOS. This phase was a game-changer. They employed an alternating batch strategy, mixing batches from both image and video datasets. This approach ensured SAM2 received a balanced diet of static and dynamic data, honing its skills in handling both images and videos with finesse.
By integrating spatial and temporal information through multi-task learning, SAM2 emerged as a groundbreaking model, adept at interpreting and segmenting complex visual data. Its training not only set new benchmarks in the field but also demonstrated how combining static and dynamic inputs can push the boundaries of AI performance.
Benchmarks
SAM2 marks a significant leap forward in video object segmentation, setting new benchmarks and vastly outperforming its predecessors.
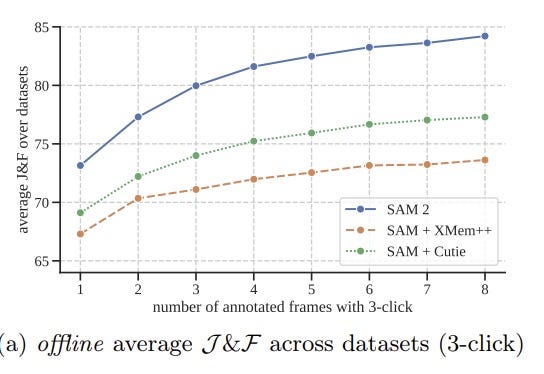
The accompanying graph illustrates SAM2’s superior performance based on the standard J&F metric. This metric is crucial for evaluating a model, as it assesses both region accuracy (via Intersection Over Union, or J) and the precision in predicting an object’s boundary (Contour Accuracy, or F). SAM2 excels in both areas, achieving a high score according to this metric.

Notably, SAM2 delivers a slightly higher accuracy (61.4% mIoU) compared to SAM (58.1% mIoU) and boasts a significant speed advantage, operating over six times faster. This improvement is largely due to the more efficient Hiera image encoder integrated into SAM2. Additionally, training on a mix of SA-1B and video data further enhances its performance, particularly in video benchmarks.
Challenges
Naturally, however there are still some concerns and challenges with any such model :
1. Computational Demands vs Accuracy : There will always be a tradeoff between using less resources and obtaining higher accuracy. SAM2 is no different. Its advanced features such as Memory Attention and Vision Transformers can require significant computational resources.
2. Handling Diverse Data : While SAM2 is trained on a large dataset and generalizes well, it can face trouble when facing new unseen or highly diverse data types. Ensuring consistent progress across all domains is difficult.
3. Ethical and Bias Concerns : As with many AI models, SAM2 could inherit the biases present within the training data, leading to ethical concerns in surveillance or medical imaging applications.
4. Complex and Fast Objects : SAM2 can sometimes miss the fine details of complex fast objects and the predictions might be unstable from frame to frame. Additional prompts can somewhat fix this issue.
5. Reliance on Manual Correction : While video segmentation has come a long way, SAM2 still needs human prompts to be more accurate. Completely automating this process could greatly improve efficiency.
Conclusion
SAM2 is a groundbreaking innovation in video and image segmentation, introducing advanced features like Memory Attention, Promptable Visual Segmentation, and a Hiera image encoder.
It excels in maintaining high accuracy across both static images and dynamic videos, all while ensuring impressive speed with a high FPS rate. This makes SAM2 an incredibly versatile tool in the AI landscape, with potential applications spanning from autonomous vehicles to video editing and medical imaging.
SAM 2 doesn’t just improve on its predecessor; it redefines the standard for segmentation models across the board, setting new benchmarks in performance and efficiency.
Want to dive deeper? Check out the resources below!
References and Further Reading
[1] SAM2 Segment Anything in Images and Videos Research Paper https://arxiv.org/abs/2408.00714
[2] SAM Segment Anything Research Paper https://arxiv.org/abs/2304.02643
[3] The 2017 Davis Challenge on Video Object Segmentation Research Paper https://arxiv.org/abs/1704.00675
[4] SAM2 Demo https://sam2.metademolab.com/demo
[5] SAM2 Blog Post by Meta AI https://ai.meta.com/blog/segment-anything-2/
[6] How to use SAM2 for Video Segmentation by Roboflow https://blog.roboflow.com/sam-2-video-segmentation/
[7] Meta’s SAM2 : The Future of Real-Time Visual Segmentation https://www.analyticsvidhya.com/blog/2024/08/meta-sam-2/